在SpringBoot中通过maven来做包管理构建,有几个地方需要注意一下的,需要解决包之间的冲突,否则运行时会报错:
(1)SparkSQL中需要先排除两个包:

1 <dependency> 2 <groupId>org.apache.spark</groupId> 3 <artifactId>spark-sql_2.11</artifactId> 4 <version>${spark.version}</version> 5 <exclusions> 6 <exclusion> 7 <groupId>org.codehaus.janino</groupId> 8 <artifactId>janino</artifactId> 9 </exclusion>10 <exclusion>11 <groupId>org.codehaus.janino</groupId>12 <artifactId>commons-compiler</artifactId>13 </exclusion>14 </exclusions>15 </dependency>(2)重新引入:
1 <dependency> 2 <groupId>org.codehaus.janino</groupId> 3 <artifactId>commons-compiler</artifactId> 4 <version>2.7.8</version> 5 </dependency> 6 7 <dependency> 8 <groupId>org.codehaus.janino</groupId> 9 <artifactId>janino</artifactId>10 <version>2.7.8</version>11 </dependency>
ok,准备工作做完之后,开始代码层面得工作:
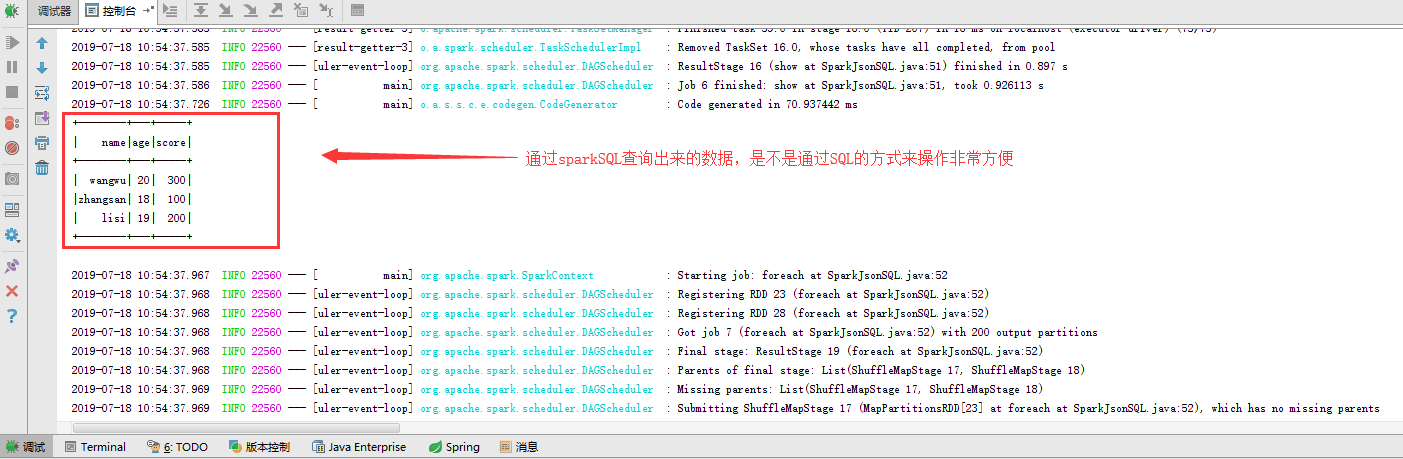
主要给大家演示的场景是将json字符串转换成临时表,然后通过sparkSQL操作临时表,非常简单方便:
1 public class SparkJsonSQL { 2 3 public void Exec(){ 4 SparkConf conf = new SparkConf(); 5 conf.setMaster("local[2]").setAppName("jsonRDD"); 6 JavaSparkContext sc = new JavaSparkContext(conf); 7 SQLContext sqlContext = new SQLContext(sc); 8 9 JavaRDD<String> nameRDD = sc.parallelize(Arrays.asList(10 "{\"name\":\"zhangsan\",\"age\":\"18\"}",11 "{\"name\":\"lisi\",\"age\":\"19\"}",12 "{\"name\":\"wangwu\",\"age\":\"20\"}"13 ));14 JavaRDD<String> scoreRDD = sc.parallelize(Arrays.asList(15 "{\"name\":\"zhangsan\",\"score\":\"100\"}",16 "{\"name\":\"lisi\",\"score\":\"200\"}",17 "{\"name\":\"wangwu\",\"score\":\"300\"}"18 ));19 20 Dataset<Row> namedf = sqlContext.read().json(nameRDD);21 Dataset<Row> scoredf = sqlContext.read().json(scoreRDD);22 namedf.registerTempTable("name");23 scoredf.registerTempTable("score");24 25 Dataset<Row> result = sqlContext.sql("select name.name,name.age,score.score from name,score where name.name = score.name");26 //Dataset<Row> result = sqlContext.sql("select * from name");27 result.show();28 result.foreach(x ->System.out.print(x));29 sc.stop();30 }31 }我们将程序运行起来看看效果: